Nếu như con người dân có kiểu học “nước mang đến chân bắt đầu nhảy”, thì vào Machine Learning cũng có thể có một thuật toán như vậy.
Bạn đang xem: Không nhãn là gì
Trong trang này:
1. Giới thiệu 3. Ví dụ như trên Python thử nghiệm 4. Bàn thảo1. Giới thiệu
Một mẩu truyện vui
Có một thằng bạn chuẩn bị đến ngày thi cuối kỳ. Vì môn này được mở tài liệu lúc thi nên anh ta không chịu đựng ôn tập để hiểu chân thành và ý nghĩa của từng bài học và mối liên hệ giữa những bài. Cầm vào đó, anh thu thập toàn bộ các tài liệu trên lớp, bao hàm ghi chép bài xích giảng (lecture notes), các slides và bài xích tập về đơn vị + lời giải. Để cho chắc, anh ta ra tủ sách và các quán Photocopy quanh trường sở hữu hết toàn bộ các nhiều loại tài liệu liên quan (khá khen mang lại cậu này siêng năng tìm tìm tài liệu). Cuối cùng, anh bạn của bọn họ thu thập được một chồng cao tư liệu để mang vào chống thi.
Vào ngày thi, anh tự tin mang ông xã tài liệu vào phòng thi. Aha, đề này ít nhất mình yêu cầu được 8 điểm. Câu 1 tương đồng bài giảng bên trên lớp. Câu 2 như nhau đề thi năm trước mà giải thuật có vào tập tài liệu cài ở tiệm Photocopy. Câu 3 gần giống với bài tập về nhà. Câu 4 trắc nghiệm thậm chí còn cậu nhớ chính xác ba tài liệu gồm ghi đáp án. Câu cuối cùng, 1 câu khó khăn nhưng anh đã từng nhìn thấy, chỉ là không nhớ ở chỗ nào thôi.
Kết trái cuối cùng, cậu ta được 4 điểm, trọn vẹn điểm qua môn. Cậu làm đúng đắn câu 1 vì tìm kiếm được ngay vào tập ghi chú bài bác giảng. Câu 2 cũng tìm được đáp án nhưng lời giải của cửa hàng Photocopy sai! Câu cha thấy gần giống bài về nhà, chỉ khác mỗi một vài thôi, cậu cho hiệu quả giống như vậy luôn, vậy mà không ăn điểm nào. Câu 4 thì tìm kiếm được cả 3 tư liệu nhưng tất cả hai trong các số đó cho câu trả lời A, cái còn sót lại cho B. Cậu chọn A cùng được điểm. Câu 5 thì không làm cho được cho dù còn tới đôi mươi phút, vày tìm mãi chẳng thấy đáp án đâu - những tài liệu vượt cũng mệt!!
Không bắt buộc ngẫu nhiên cơ mà tôi dành ra cha đoạn văn để kể về chuyện học tập của anh chàng kia. Hôm nay tôi xin trình diễn về một cách thức trong Machine Learning, được hotline là K-nearest neighbor (hay KNN), một thuật toán được xếp vào các loại lazy (machine) learning (máy lười học). Thuật toán này khá tương tự với giải pháp học/thi của anh bạn kém như ý kia.
K-nearest neighbor
K-nearest neighbor là trong những thuật toán supervised-learning đơn giản nhất (mà tác dụng trong một vài trường hợp) vào Machine Learning. Khi training, thuật toán này không học một điều gì từ tài liệu training (đây cũng là vì sao thuật toán này được xếp vào nhiều loại lazy learning), mọi đo lường được triển khai khi nó đề xuất dự đoán tác dụng của dữ liệu mới. K-nearest neighbor hoàn toàn có thể áp dụng được vào cả hai các loại của việc Supervised learning là Classification và Regression. KNN có cách gọi khác là một thuật toán Instance-based tuyệt Memory-based learning.
Có một vài khái niệm khớp ứng người-máy như sau:
| Câu hỏi | Điểm dữ liệu | Data point |
| Đáp án | Đầu ra, nhãn | Output, Label |
| Ôn thi | Huấn luyện | Training |
| Tập tài liệu sở hữu vào chống thi | Tập tài liệu tập huấn | Training set |
| Đề thi | Tập dữ liểu kiểm thử | Test set |
| Câu hỏi trong dề thi | Dữ liệu kiểm thử | Test data point |
| Câu hỏi bao gồm đáp án sai | Nhiễu | Noise, Outlier |
| Câu hỏi sát giống | Điểm dữ liệu gần nhất | Nearest Neighbor |
Với KNN, trong bài toán Classification, label của một điểm tài liệu mới (hay công dụng của câu hỏi trong bài xích thi) được suy ra trực tiếp từ K điểm dữ liệu gần nhất trong training set. Label của một test data hoàn toàn có thể được quyết định bằng major voting (bầu lựa chọn theo số phiếu) giữa những điểm ngay gần nhất, hoặc nó rất có thể được suy ra bằng phương pháp đánh trọng số khác nhau cho từng trong các điểm sớm nhất đó rồi suy ra label. Cụ thể sẽ được nêu vào phần tiếp theo.
Trong việc Regresssion, cổng đầu ra của một điểm dữ liệu sẽ bởi chính đầu ra của điểm dữ liệu đã biết gần nhất (trong trường đúng theo K=1), hay những trung bình bao gồm trọng số của đầu ra của không ít điểm ngay gần nhất, hoặc bằng một quan hệ dựa trên khoảng cách tới các điểm gần nhất đó.
Một cách ngắn gọn, KNN là thuật toán đi tìm kiếm đầu ra của một điểm dữ liệu mới bằng phương pháp chỉ dựa trên thông tin của K điểm tài liệu trong training set gần nó nhất (K-lân cận), không suy nghĩ việc bao gồm một vài ba điểm dữ liệu trong những điểm sớm nhất này là nhiễu. Hình dưới đó là một lấy ví dụ về KNN vào classification với K = 1.
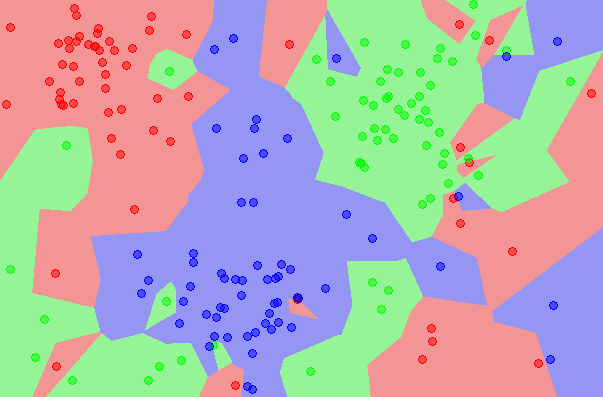
Ví dụ trên đây là bài toán Classification cùng với 3 classes: Đỏ, Lam, Lục. Từng điểm tài liệu mới (test data point) sẽ tiến hành gán label theo màu sắc của điểm mà lại nó trực thuộc về. Vào hình này, tất cả một vài ba vùng bé dại xem lẫn vào những vùng lớn hơn khác màu. Ví dụ có một điểm color Lục ở sát góc 11 giờ nằm giữa hai vùng lớn với khá nhiều dữ liệu color Đỏ và Lam. Điểm này rất rất có thể là nhiễu. Dẫn mang đến nếu dữ liệu test lâm vào vùng này sẽ có rất nhiều khả năng cho hiệu quả không chính xác.
Khoảng cách trong không khí vector
Trong không gian một chiều, khoảng cách giữa nhị điểm là trị tuyệt vời nhất giữa hiệu quý giá của hai điểm đó. Trong không khí nhiều chiều, khoảng cách giữa hai điểm rất có thể được định nghĩa bởi nhiều hàm số không giống nhau, trong các số ấy độ dài đường thằng nổi hai điểm chỉ là một trong những trường hợp quan trọng đặc biệt trong đó. Nhiều thông tin bổ ích (cho Machine Learning) hoàn toàn có thể được tìm kiếm thấy trên Norms (chuẩn) của vector trong tab Math.
2. đối chiếu toán học
Thuật toán KNN rất dễ hình dung nên đang phần “Phân tích toán học” này vẫn chỉ bao gồm 3 câu. Tôi thẳng đi vào các ví dụ. Có một điều đáng xem xét là KNN buộc phải nhớ toàn bộ các điểm tài liệu training, việc này không được lợi về cả bộ nhớ và thời gian đo lường và thống kê - y hệt như khi đứa bạn của chúng ta không tìm được câu trả lời cho thắc mắc cuối cùng.
3. Ví dụ như trên Python
Bộ cơ sở dữ liệu Iris (Iris flower dataset).
Iris flower dataset là 1 trong bộ dữ liệu nhỏ dại (nhỏ hơn không ít so cùng với MNIST. Bộ dữ liệu này bao hàm thông tin của tía loại hoa Iris (một loài hoa lan) không giống nhau: Iris setosa, Iris virginica cùng Iris versicolor. Mỗi loại có 50 nhành hoa được đo với tài liệu là 4 thông tin: chiều dài, chiều rộng lớn đài hoa (sepal), cùng chiều dài, chiều rộng cánh hoa (petal). Dưới đây là ví dụ về hình ảnh của ba loại hoa. (Chú ý, đây không hẳn là cỗ cơ sở dữ liệu ảnh như MNIST, từng điểm dữ liệu trong tập này chỉ là một vector 4 chiều).

Bộ dữ liệu bé dại này thường được sử dụng trong vô số nhiều thuật toán Machine Learning trong số lớp học. Tôi sẽ lý giải lý vị không chọn MNIST vào phần sau.
Thí nghiệm
Trong phần này, chúng ta sẽ bóc tách 150 dữ liệu trong Iris flower dataset ra thành 2 phần, hotline là training set và test set. Thuật toán KNN sẽ nhờ vào trông tin sống training set để tham dự đoán coi mỗi tài liệu trong test set khớp ứng với loại hoa nào. Tài liệu được dự đoán này sẽ được so sánh với loại hoa thật của mỗi dữ liệu trong test set để đánh giá kết quả của KNN.
Trước tiên, họ cần khai báo vài thư viện.
Iris flower dataset tất cả sẵn trong thư viện scikit-learn.
Tiếp theo, chúng ta load dữ liệu và hiện thị vài dữ liệu mẫu. Các class được gán nhãn là 0, 1, và 2.
iris = datasets.load_iris()iris_X = iris.datairis_y = iris.targetprint "Number of classes: %d" %len(np.unique(iris_y))print "Number of data points: %d" %len(iris_y)X0 = iris_X
Samples from class 0:
", X0<:5,:>X1 = iris_X
Samples from class 1:
", X1<:5,:>X2 = iris_X
Samples from class 2:
", X2<:5,:>
Kết quả cho thấy label dự đoán gần giống với label thật của kiểm tra data, chỉ có 2 điểm trong các 20 điểm được hiển thị có công dụng sai lệch. Ở đây họ làm quen với quan niệm mới: ground truth. Một cách solo giản, ground truth đó là nhãn/label/đầu ra thực sự của những điểm trong thử nghiệm data. Có mang này được sử dụng nhiều trong Machine Learning, hy vọng lần tới chúng ta gặp thì sẽ nhớ ngay nó là gì.
Để reviews độ đúng mực của thuật toán KNN classifier này, chúng ta xem xem có bao nhiêu điểm trong test data được dự kiến đúng. Lấy con số này phân tách cho tổng con số trong tập demo data vẫn ra độ chủ yếu xác. Scikit-learn cung cấp hàm số accuracy_score để thực hiện các bước này.
from sklearn.metrics import accuracy_scoreprint "Accuracy of 1NN: %.2f %%" %(100*accuracy_score(y_test, y_pred))
Classifier)
Nhận thấy rằng chỉ xét 1 điều gần nhất hoàn toàn có thể dẫn đến công dụng sai nếu đặc điểm này là nhiễu. Một cách hoàn toàn có thể làm tăng độ và đúng là tăng số lượng điểm kề bên lên, ví dụ như 10 điểm, với xem xem trong 10 điểm gần nhất, class như thế nào chiếm đa số thì dự đoán tác dụng là class đó. Kỹ thuật dựa vào nhiều phần này được call là major voting.
clf = neighbors.KNeighbors
Classifier(n_neighbors = 10, phường = 2)clf.fit(X_train, y_train)y_pred = clf.predict(X_test)print "Accuracy of 10NN with major voting: %.2f %%" %(100*accuracy_score(y_test, y_pred))
Kết trái đã tăng thêm 98%, cực kỳ tốt!
Là một kẻ tham lam, tôi chưa mong dừng tác dụng ở đây vì thấy rằng mình vẫn đang còn thể nâng cao được. Trong chuyên môn major voting bên trên, mỗi trong 10 điểm sớm nhất được xem là có vai trò tương đồng và cực hiếm lá phiếu của mỗi đặc điểm này là như nhau. Tôi mang đến rằng như vậy là ko công bằng, vì rõ ràng rằng những điểm ngay gần hơn nên có trọng số cao hơn nữa (càng thân cận thì sẽ càng tin tưởng). Vậy phải tôi vẫn đánh trọng số khác nhau cho từng trong 10 điểm sớm nhất này. Phương pháp đánh trọng số buộc phải thoải mãn điều kiện là 1 trong điểm càng ngay sát điểm demo data thì bắt buộc được tấn công trọng số càng cao (tin tưởng hơn). Cách đơn giản nhất là lấy nghịch đảo của khoảng cách này. (Trong ngôi trường hợp chạy thử data trùng với cùng một điểm dữ liệu trong training data, tức khoảng cách bằng 0, ta lấy luôn label của điểm training data).
Xem thêm: Các Cụ Dạy: Trước Nhà Trồng Cây Ăn Quả Gì Trước Nhà, Nên Trồng Cây Gì Trước Nhà
Scikit-learn giúp họ đơn giản hóa vấn đề này bằng phương pháp gán gía trị weights = "distance". (Giá trị mang định của weights là "uniform", khớp ứng với việc coi toàn bộ các điểm bên cạnh có giá trị như nhau như sinh hoạt trên).
clf = neighbors.KNeighbors
Classifier(n_neighbors = 10, p = 2, weights = "distance")clf.fit(X_train, y_train)y_pred = clf.predict(X_test)print "Accuracy of 10NN (1/distance weights): %.2f %%" %(100*accuracy_score(y_test, y_pred))
Aha, 100%.
Chú ý: xung quanh 2 phương thức đánh trọng số weights = "uniform" cùng weights = "distance" sinh hoạt trên, scikit-learn còn cung cấp cho họ một cách để đánh trọng số một bí quyết tùy chọn. Ví dụ, một bí quyết đánh trọng số phổ cập khác vào Machine Learning là:
trong đó (mathbfx) là thử nghiệm data, (mathbfx_i) là 1 trong những điểm trong K-lân cận của (mathbfx), (w_i) là trọng số của đặc điểm đó (ứng với điểm tài liệu đang xét (mathbfx)), (sigma) là một trong những dương. Nhận ra rằng hàm số này cũng thỏa mãn điều kiện: điểm càng ngay sát (mathbfx) thì trọng số càng tốt (cao nhất bởi 1). Cùng với hàm số này, chúng ta cũng có thể lập trình như sau:
def myweight(distances): sigma2 = .5 # we can change this number return np.exp(-distances**2/sigma2)clf = neighbors.KNeighbors
Classifier(n_neighbors = 10, phường = 2, weights = myweight)clf.fit(X_train, y_train)y_pred = clf.predict(X_test)print "Accuracy of 10NN (customized weights): %.2f %%" %(100*accuracy_score(y_test, y_pred))
Trong trường hòa hợp này, tác dụng tương đương với nghệ thuật major voting. Để tiến công giá đúng đắn hơn kết quả của KNN với K khác nhau, bí quyết định nghĩa khoảng tầm cách không giống nhau và phương pháp đánh trọng số không giống nhau, họ cần thực hiện quy trình trên với nhiều phương pháp chia tài liệu training với test không giống nhau rồi lấy công dụng trung bình, vày rất hoàn toàn có thể dữ liệu phân chia trong 1 trường hợp cụ thể là tốt nhất có thể hoặc rất xấu (bias). Đây cũng là cách thường được sử dụng khi nhận xét hiệu năng của một thuật toán cụ thể nào đó.
4. Thảo luận
KNN cho Regression
Với bài toán Regression, họ cũng trả toàn có thể sử dụng cách thức tương tự: mong lượng đầu ra dựa trên đầu ra và khoảng cách của những điểm trong K-lân cận. Bài toán ước lượng ra sao các chúng ta cũng có thể tự tư tưởng tùy vào từng bài xích toán.

Chuẩn hóa dữ liệu
Khi tất cả một ở trong tính trong tài liệu (hay bộ phận trong vector) lớn hơn các trực thuộc tính khác tương đối nhiều (ví dụ thay vị đo bằng cm thì một tác dụng lại tính bởi mm), khoảng cách giữa các điểm sẽ dựa vào vào trực thuộc tính này hết sức nhiều. Để đã đạt được kết quả đúng mực hơn, một kỹ thuật thường được dùng là Data Normalization (chuẩn hóa dữ liệu) để mang các nằm trong tính có đơn vị đo không giống nhau về cùng một khoảng tầm giá trị, hay là tự 0 mang đến 1, trước khi thực hiện KNN. Có khá nhiều kỹ thuật chuẩn chỉnh hóa không giống nhau, các bạn sẽ được thấy khi thường xuyên theo dõi Blog này. Các kỹ thuật chuẩn chỉnh hóa được áp dụng với không chỉ KNN bên cạnh đó với phần đông các thuật toán khác.
Sử dụng những phép đo khoảng cách khác nhau
Ngoài norm 1 và norm 2 tôi giới thiệu trong bài xích này, còn rất nhiều các khoảng cách khác nhau hoàn toàn có thể được dùng. Một ví dụ đơn giản là đếm số lượng thuộc tính khác biệt giữa hai điểm dữ liệu. Số này càng nhỏ dại thì hai điểm càng gần nhau. Đây đó là giả chuẩn 0 nhưng tôi đã reviews trong Tab Math.
Ưu điểm của KNN
Độ phức tạp tính toán của quá trình training là bởi 0. Câu hỏi dự đoán kết quả của dữ liệu mới rất đối kháng giản. Không đề xuất giả sử gì về phân phối của các class.Nhược điểm của KNN
KNN rất nhạy cảm cùng với nhiễu khi K nhỏ. Như đang nói, KNN là 1 trong thuật toán mà mọi giám sát đều nằm tại vị trí khâu test. Trong những số ấy việc tính khoảng cách tới từng điểm dữ liệu trong training set đang tốn không ít thời gian, đặc biệt là với những cơ sở tài liệu có số chiều khủng và có tương đối nhiều điểm dữ liệu. Với K càng lớn thì độ phức tạp cũng sẽ tăng lên. Xung quanh ra, việc lưu tổng thể dữ liệu trong bộ nhớ cũng tác động tới tính năng của KNN.Tăng tốc mang đến KNN
Ngoài việc thống kê giám sát khoảng cách xuất phát từ một điểm kiểm tra data đến tất cả các điểm trong traing set (Brute Force), có một vài thuật toán khác giúp tăng tốc việc đào bới tìm kiếm kiếm này. Bạn đọc có thẻ kiếm tìm kiếm thêm với nhì từ khóa: K-D Tree cùng Ball Tree. Tôi xin dành phần này cho người hâm mộ tự kiếm tìm hiểu, với sẽ quay lại nếu gồm dịp. Bọn họ vẫn còn đa số thuật toán quan trọng đặc biệt hơn khác nên nhiều sự quan tâm hơn.
Try this yourself
Tôi bao gồm viết một quãng code ngắn để triển khai việc Classification cho cơ sở dữ liệu MNIST. Chúng ta hãy download cục bộ bộ tài liệu này về vày sau này chúng ta còn sử dụng nhiều, chạy thử, bình luận kết quả và nhận xét của các bạn vào phần comment bên dưới. Để vấn đáp cho câu hỏi vì sao tôi không chọn cơ sở dữ liệu này làm ví dụ, bạn đọc rất có thể tự kiếm tìm ra đáp án khi chạy kết thúc đoạn code này.
Enjoy!
# %resetimport numpy as np from mnist import MNIST # require `pip install python-mnist`# https://pypi.python.org/pypi/python-mnist/import matplotlib.pyplot as pltfrom sklearn import neighborsfrom sklearn.metrics import accuracy_scoreimport time# you need to download the MNIST dataset first# at: http://yann.lecun.com/exdb/mnist/mndata = MNIST("../MNIST/") # path to your MNIST folder mndata.load_testing()mndata.load_training()X_test = mndata.test_images
X_train = mndata.train_imagesy_test = np.asarray(mndata.test_labels)y_train = np.asarray(mndata.train_labels)start_time = time.time()clf = neighbors.KNeighbors
Classifier(n_neighbors = 1, p = 2)clf.fit(X_train, y_train)y_pred = clf.predict(X_test)end_time = time.time()print "Accuracy of 1NN for MNIST: %.2f %%" %(100*accuracy_score(y_test, y_pred))print "Running time: %.2f (s)" % (end_time - start_time)
Nếu bao gồm câu hỏi, bạn cũng có thể để lại comment dưới hoặc trên forums để nhận ra câu vấn đáp sớm hơn.Bạn đọc hoàn toàn có thể ủng hộ blog qua "Buy me a cofee" ở góc trên bên trái của blog.Tôi vừa xong xuôi cuốn ebook "Machine Learning cơ bản", chúng ta có thể đặt sách tại đây.Cảm ơn bạn.
Trong đồ vật học, gắn nhãn dữ liệu là thừa trình xác định dữ liệu thô (hình ảnh, tệp văn bản, video, v.v.) với thêm một hoặc các nhãn gồm nghĩa với chứa thông tin hữu ích để cung ứng ngữ cảnh cho quy mô máy học hoàn toàn có thể học hỏi tự đó. Ví dụ: nhãn có thể cho biết hình ảnh chứa con chim tốt ô tô, mọi từ như thế nào được phát ra trong bản ghi âm hoặc liệu hình ảnh chụp X-quang tất cả chứa khối u tốt không. Ghi nhãn dữ liệu là tiến trình bắt buộc so với nhiều trường vừa lòng sử dụng, bao hàm cả thị giác lắp thêm tính, xử trí ngôn ngữ tự nhiên và thoải mái vànhận diện giọng nói.
Hiện nay, hầu như các quy mô máy học thực tiễn đều sử dụng phương thức học bao gồm giám sát. Phương thức này vận dụng thuật toán nhằm ánh xạ một nguồn vào đến một đầu ra. Để phương pháp học bao gồm giám sát chuyển động hiệu quả, các bạn cần hỗ trợ một tập dữ liệu được ghi nhãn nhằm mục đích đào tạo mô hình này gửi ra đưa ra quyết định chính xác. Các bước ghi nhãn tài liệu thường bắt đầu bằng vấn đề yêu cầu con người đánh giá về một dữ liệu cụ thể chưa được ghi nhãn. Ví dụ: Đặt ra thắc mắc “ảnh gồm chứa chim không” với yêu cầu fan ghi nhãn gắn thẻ toàn bộ những hình hình ảnh trong tập dữ liệu vừa lòng câu trả lời “có”. Làm việc gắn thẻ hoàn toàn có thể chỉ dễ dàng là vấn đáp có/không, nhưng cũng có thể cụ thể như là xác định các điểm hình ảnh cụ thể trong hình hình ảnh có tương quan đến chim. Mô hình máy học sẽ thực hiện nhãn do nhỏ người hỗ trợ để học những mẫu hình cơ phiên bản trong một quy trình mang tên là “đào sinh sản mô hình”. Cuối cùng, chúng ta có một mô hình được đào tạo, hoàn toàn có thể dùng để lấy ra dự đoán về tài liệu mới.
Trong lắp thêm học, tập dữ liệu được ghi nhãn thích hợp mà bạn áp dụng làm tiêu chuẩn chỉnh khách quan tiền để giảng dạy và đánh giá một quy mô nhất định thường được gọi là “sự thật nền tảng”. Độ đúng chuẩn của quy mô được đào tạo và giảng dạy sẽ nhờ vào vào độ đúng chuẩn của thực sự nền tảng. Bởi vì vậy, việc dành thời gian và nguồn lực để bảo vệ ghi nhãn tài liệu với độ đúng mực cao là rất đề xuất thiết.
Thị giác máy tính
Khi xây dựng khối hệ thống thị giác máy tính, trước tiên bạn phải ghi nhãn hình ảnh, điểm ảnh, điểm chính hoặc chế tác một đường viền bảo phủ hoàn toàn hình ảnh kỹ thuật số, call là vỏ hộp giới hạn, để chế tác tập dữ liệu đào tạo. Ví dụ: bạn cũng có thể phân nhiều loại hình hình ảnh theo loại chất lượng (như hình hình ảnh sản phẩm đối với hình ảnh trong bối cảnh đời thường) hoặc văn bản (những gì thực sự xuất hiện trong hình ảnh đó). Bạn cũng có thể phân đoạn hình hình ảnh theo lever điểm ảnh. Sau đó, bạn cũng có thể sử dụng dữ liệu giảng dạy này nhằm mục tiêu xây dựng mô hình thị giác máy tính xách tay dùng để auto phân mô hình ảnh, vạc hiện địa điểm đối tượng, xác minh điểm thiết yếu trong hình ảnh hoặc phân đoạn hình ảnh.
Xử lý ngôn ngữ tự nhiên
Khi xử lý ngôn ngữ tự nhiên, trước tiên các bạn phải xác định thủ công bằng tay các phần quan trọng đặc biệt trong văn bản hoặc thêm thẻ văn phiên bản bằng các nhãn rõ ràng để chế tác tập tài liệu đào tạo. Ví dụ: có thể bạn muốn xác định cảm hứng hoặc mục đích của một đoạn văn bản, xác định từ loại, phân loại danh từ riêng như địa điểm, con người và xác định văn phiên bản trong hình ảnh, tệp PDF hoặc những tệp khác. Để tiến hành việc này, chúng ta có thể vẽ các hộp giới hạn xung quanh văn bản, rồi chép lại văn bản bằng cách thủ công bằng tay vào tập tài liệu đào tạo. Các mô hình xử lý ngôn ngữ thoải mái và tự nhiên được thực hiện để so sánh cảm xúc, nhấn dạng thương hiệu thực thể và nhận dạng ký kết tự quang đãng học.
Xử lý âm thanh
Xử lý âm nhạc sẽ thay đổi tất cả các loại âm nhạc như lời nói, giờ ồn tự nhiên (tiếng sủa, còi xe hoặc giờ đồng hồ hót) và music trong nhà (tiếng kính vỡ, tiếng vật dụng quét hoặc giờ báo động) thành định dạng có kết cấu để rất có thể dùng trong thiết bị học. Khi xử trí âm thanh, trước tiên chúng ta thường yêu cầu chép âm bằng phương pháp thủ công thành văn bạn dạng viết. Từ bỏ đó, chúng ta cũng có thể khám phá thông tin sâu hơn về âm thanh bằng phương pháp thêm thẻ với phân một số loại âm thanh. Âm thanh được phân một số loại này sẽ trở nên tập dữ liệu đào tạo và huấn luyện của bạn.
Có nhiều kỹ thuật giúp nâng cao tính tác dụng và chính xác của bài toán ghi nhãn dữ liệu. Có thể kể mang đến một vài nghệ thuật như:
Giao diện quá trình trực quan và được bố trí hợp lý sẽ giúp giảm thiểu thiết lập nhận thức và vấn đề phải thay đổi ngữ cảnh cho tất cả những người ghi nhãn. Sự đồng thuận giữa đội ngũ ghi nhãn để giúp đỡ tránh lỗi/sai lệch của các người chú thích riêng lẻ. Để tạo sự đồng thuận giữa đội ngũ ghi nhãn, phải gửi từng đối tượng người tiêu dùng trong tập dữ liệu cho đa số người chú thích, kế tiếp hợp nhất các phản hồi của họ (được call là “chú thích”) thành một nhãn duy nhất. Kiểm tra nhãn để xác minh tính đúng đắn của nhãn và update nhãn khi đề xuất thiết. Học chủ động để ghi nhãn dữ liệu kết quả hơn bằng cách sử dụng vật dụng học nhằm khẳng định dữ liệu cân xứng nhất để con bạn ghi nhãn.Các quy mô machine learning thành công xuất sắc được thi công trên một cân nặng lớn dữ liệu đào tạo có quality cao. Cơ mà quy trình tạo thành dữ liệu đào tạo cần thiết để chế tạo các quy mô này thường đắt đỏ, phức tạp và tốn thời gian. Phần nhiều các mô hình được tạo nên ra hiện thời yêu cầu con tín đồ ghi nhãn tài liệu theo cách bằng tay thủ công nhằm góp cho quy mô học phương pháp đưa ra đưa ra quyết định chính xác. Để vượt qua thử thách này, bạn có thể nâng cao tác dụng ghi nhãn bằng phương pháp sử dụng quy mô máy học nhằm ghi nhãn dữ liệu tự động. Trong quá trình này, thứ nhất thì mô hình máy học ghi nhãn dữ liệu sẽ được đào tạo dựa trên một tập vừa lòng con dữ liệu thô đã có được con người ghi nhãn. Vào trường hợp tác dụng của quy mô ghi nhãn có độ tin tưởng cao dựa trên những gì đang học bấy lâu, mô hình sẽ auto áp dụng nhãn cho dữ liệu thô. Trong trường hợp tác dụng của quy mô ghi nhãn có độ tin tưởng thấp hơn, mô hình sẽ chuyển tài liệu để con tín đồ ghi nhãn. Sau đó, quy mô ghi nhãn lại nhận được nhãn do bé người tạo ra để học tập và nâng cấp khả năng auto ghi nhãn đến tập tài liệu thô tiếp theo. Dần dần, mô hình này gồm thể tự động ghi nhãn ngày dần nhiều dữ liệu hơn và tăng tốc đáng kể cho vấn đề tạo những tập tài liệu đào tạo.

thietkenhaxinh.com Sage
Maker Ground Truth giúp bớt đáng kể thời hạn và công sức quan trọng để chế tác tập tài liệu cho mục đích đào tạo. Sage
Maker Ground Truth cho phép bạn tiếp cận đội hình nngười ghi nhãn chỗ đông người và riêng biệt tư, đồng thời cung cấp cho họ những giao diện cùng quy trình thao tác tích hợp sẵn giành riêng cho các trọng trách ghi nhãn phổ biến. Dễ dàng dàng bước đầu sử dụng Sage
Maker Ground Truth. Bạn cũng có thể sử dụng phía dẫn ban đầu để tạo công việc ghi nhãn đầu tiên chỉ vào vài phút. bước đầu Ghi nhãn dữ liệu trên thietkenhaxinh.com bằng phương pháp tạo thông tin tài khoản ngay hôm nay.












